K-NN or K-Nearest Neighbor works on the simple principle- “Birds of the same feather flock together.”
K-NN is a Supervised Machine Learning Algorithm. It solves both Regression and Classification problems. And mostly used for Classification problems. It classifies the data points based on how its neighbours are classified. The algorithm classifies new data point by looking at its k already- classified, nearest neighbours.
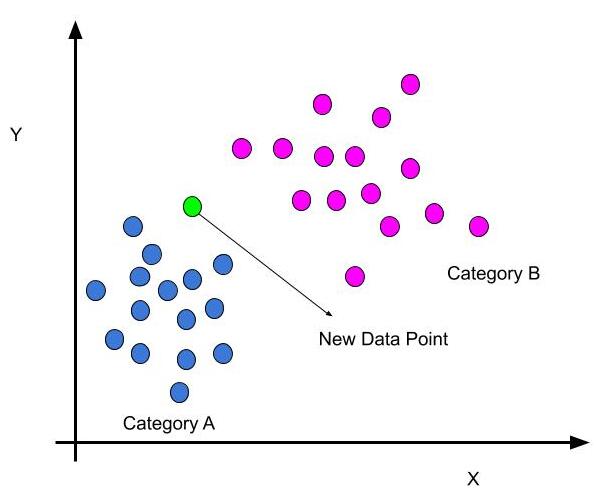
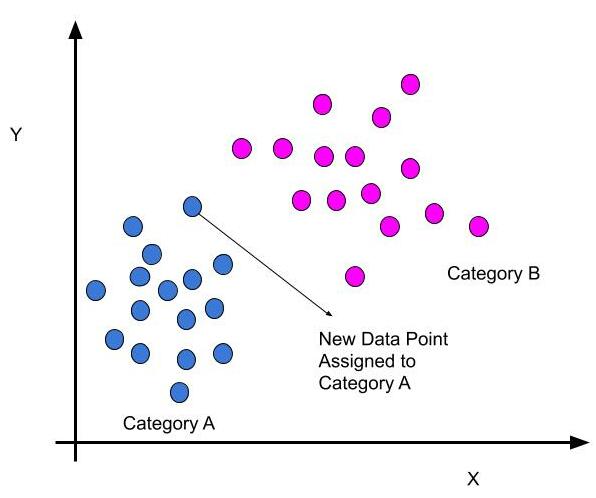
How do K-NN works?
- Select the value of K.
- Calculate the Euclidean distance of the K number of neighbour. Euclidean distance between two points A and B is √(x2−x1)^2+(y2−y1)^2
- Take the K nearest neighbours according to the calculated Euclidean distance(take the smallest distance).
- Count the number of data points in each category obtained from k- neighbours.
- Assign the new data points to that category where the number of neighbours is maximum.
- Our model is ready.
What is K in the K-NN Algorithm?
K-NN Algorithm is based on feature similarity. It is the simple and most used Supervised learning algorithm. Here, K is the number of nearest neighbours that helps to assign a label to the current point. Choosing the value of K is the most critical problem and is the most important step. The process to select K-value is “parameter tuning“.
- Low values of K such as 1 or 2 can be noisy so not suitable to use.
- Large values of K may find some difficulties.
- There is no formula to find the value of K. So we need to try some values to find the best value of K(Preferred value = 5).
When to use K-NN
- Labelled dataset.
- On small dataset, because the classifier completes execution in a shorter time period.
- Noise-free data.
Different Names of KNN Algorithm
- Memory-Based Reasoning
- Example-Based Reasoning
- Instance-Based Reasoning
- Case-Based Reasoning
- Lazy Learning
Why K-NN is Lazy Learning Algorithm?
According to Lazy Learning, there is no need to learn or train the model. All the data points are used at the time of prediction. It stores all the training dataset and waits until classification needs to perform. Unlike eager learners, they perform less work in the training stage and more in the testing phase to solve classification problems.
Advantages of K-NN
- Simple to understand and implement.
- Need not make additional assumptions.
- Used in Regression, Classification and as well as Searching problems.
- If the sample input is large, then the model can be good classified.
- There is no prior knowledge or very little knowledge of data distribution.
- Can apply to any data, since does not depend on its distribution.
- When building a K-NN model, we have different methods to measure distance based on the nature of features:
- Euclidean distance
- Manhattan distance
- Hamming distance
Disadvantages of K-NN
- Selecting K may be tricky.
- No training. Therefore, work done in testing.
- Testing is computationally expensive.
- Sensitive to irrelevant attributes.
- Performance depends upon the number of dimensions used.
- Need large sample data for accuracy.
- Need high memory storage when compared to other Supervised Machine Learning Algorithm.
- Can’t tackle missing values.
Applications of K-NN
- For classification.
- To get missing values.
- Pattern recognition.
- Banking System.
- Recommender Systems.
- Video recognition
- Image recognition.
- Handwriting detection.
